
Table des matières
- Les clés pour gérer les logs
- Utiliser les “Regular expressions”
- Extraire du contenu grâce aux expressions régulières
- Utiliser le paramètre “maxdelay”
- Utiliser les Tags et la corrélation locale
Les clés pour gérer les logs
Zabbix propose, nativement, 2 clés pour superviser nos logs en mode actif :
- log()
- logrt()
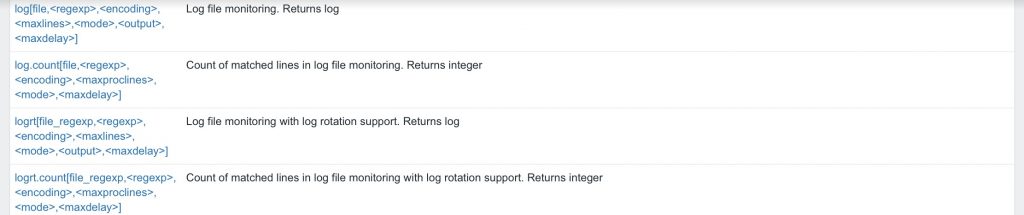
Ces deux clés font la même chose, enfin presque, la clé logrt(), avec « rt » pour rotation, permet de pouvoir spécifier une regex pour la recherche de fichiers à parcourir.
Notes
Et depuis la version 3.2 de Zabbix, il est possible de savoir combien de lignes ont matchés nos critères de recherche avec les clés :
- log.count()
- logrt.count()
Un exemple d’utilisation de la clé logrt() :
En envoyant au maximum 100 lignes des fichiers du dossier “/home/user/” dont le nom commence par “logfile” et se termine par les chiffres qui vont de 001 à 999.
Bien sûr, seulement le fichier écrit le plus récemment sera parcourus par l’agent Zabbix.
logrt["/home/user/^logfile[0—9]{1,3}$",,,100]
Utiliser les “Regular expressions”
Et au niveau du pattern de recherche, pourquoi ne pas tirer parti de la puissance des “Regular expressions” de Zabbix afin de combiner tous vos critères de recherche à un même endroit.
La création de nouvelles expressions régulières se fait depuis le menu “Administration – General” et nous sélectionnons “Regular expressions” dans la liste déroulante.
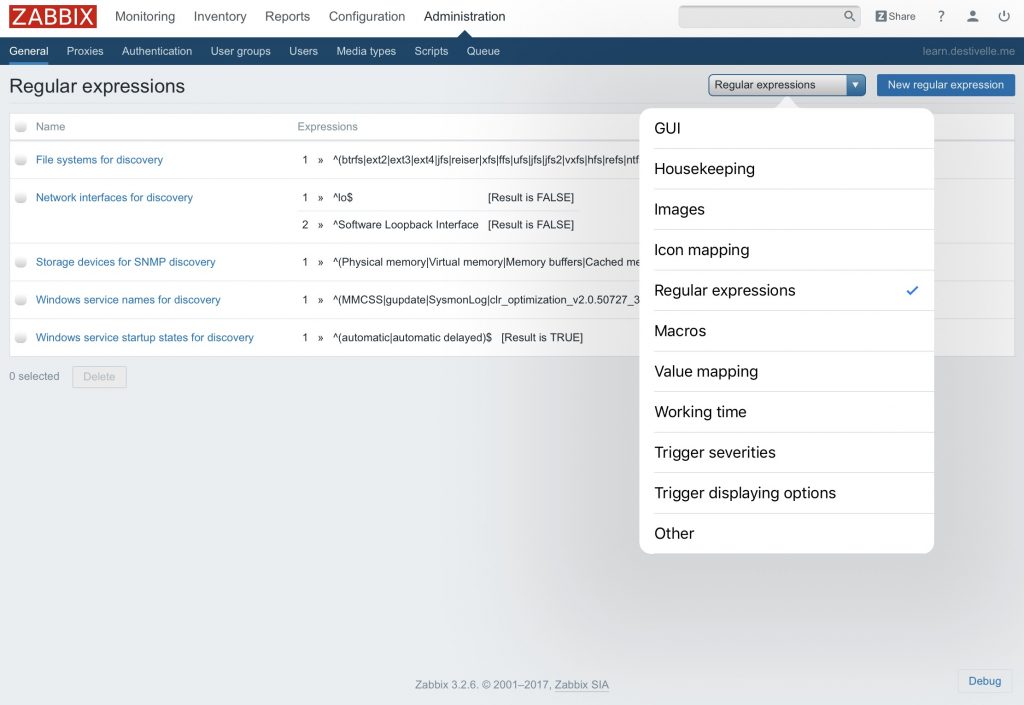
Prenons l’exemple ici de l’expression régulière “Log file regular expression” dont le contenu est le suivant :
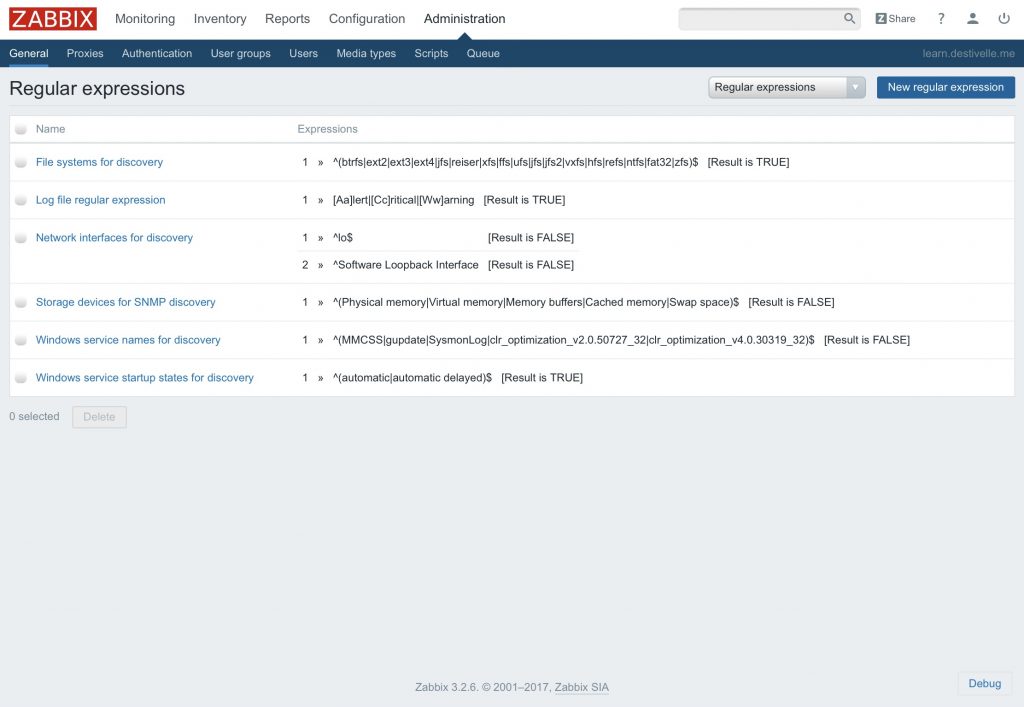 En détail :
En détail :
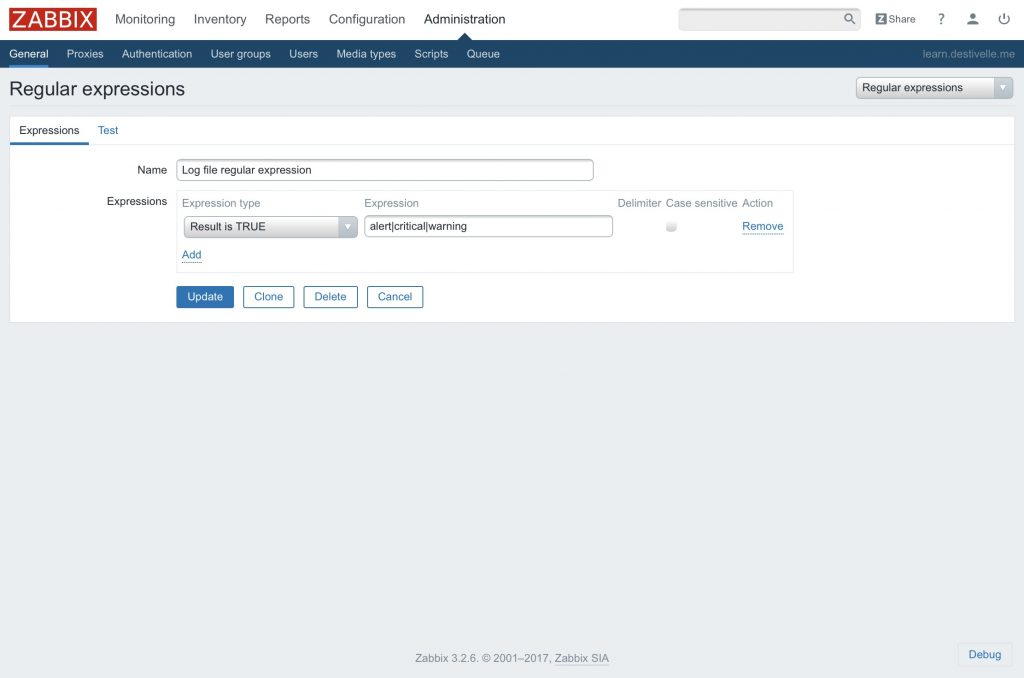
Mon expression régulière valide la présence des mots suivants peu importe leur casse :
- Alert
- Critical
- Warning
Donc dans notre exemple, Zabbix va parcourir tous les fichiers correspondant à l’expression rationnelle « logfile[0-9]{1,3}$ », à la recherche des chaînes de caractères que nous avons définis dans notre expression régulière.
Un peu d’optimisation afin de réduire la charge CPU.
Nous pouvons utiliser le mode « SKIP » pour ne pas parcourir de nouveau les lignes déjà analysées.
logrt["/home/user/^logfile[0—9]{1,3}$","@Log file regular expression",,,skip]
Extraire du contenu grâce aux expressions régulières
Il peut arriver que nous ayons envie d’extraire une information précise d’un log plutôt que d’afficher la ligne entière.
Prenons par exemple l’item suivant :
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+)",,,,\1]
La définition de celui-ci nous permet d’extraire de la ligne suivante la valeur numérique de “Entries” :
Fr Feb 07 2014 11:07:36.6690 */ Thread Id 1400 large result
buffer allocation - /Length: 437136/Entries: 5948/Client Version:10 ID: 41726453/User: User/Form: CFG:ServiceLevelAgreement
Ce qui nous permet d’extraire uniquement la valeur numérique de “Entries” est que nous definissons le paramètre “output” à “\1”.
Ce qui nous permet de récupérer la valeur du premier groupe ([0-9]+).
Et, de ce fait, ce chiffre que nous avons extrait de notre log peut être utilisé dans un trigger afin de pouvoir être alerté.
Pour récupérer également la valeur de “Version”, nous aurions utilisé l’item suivant :
log[/path/to/the/file,"large result buffer allocation.*Entries: ([0-9]+).*Version:([0-9]+)",,,,"Entries: \1 Version: \2"]
Utiliser le paramètre “maxdelay”
Le paramètre “maxdelay”, exprimé en secondes, permet lors de l’analyse d’un log d’ignorer un certain nombre de lignes afin d’obtenir les lignes les plus récentes analysées dans les secondes ‘maxdelay’.
Utiliser les Tags et la corrélation locale
Et si nous appliquions les tags et la corrélation locale pour obtenir le meilleur de nos logs.
Soit le fichier de log suivant “/var/log/services” qui contient l’état de plusieurs services :
…
10/Aug/2016:06:25:30 service Jira stopped
10/Aug/2016:06:25:32 service MySQL stopped
10/Aug/2016:06:26:11 service MySQL started
10/Aug/2016:06:26:22 service Redis stopped
10/Aug/2016:06:26:58 service Redis started
10/Aug/2016:06:27:31 service Jira started
…
L’utilisation des tags et de la corrélation locale nous permettrait de ne définir qu’un seul item et qu’un seul trigger pour nous donner des informations sur l’état des 3 services en exemple.
Notre item serait défini comme suit :
log(/var/log/services)
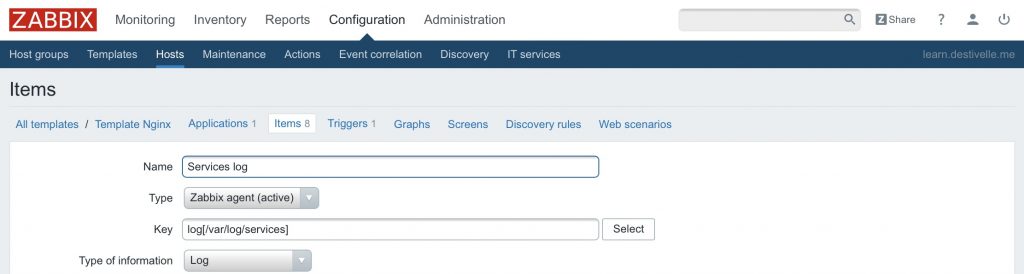
Et notre trigger ainsi :
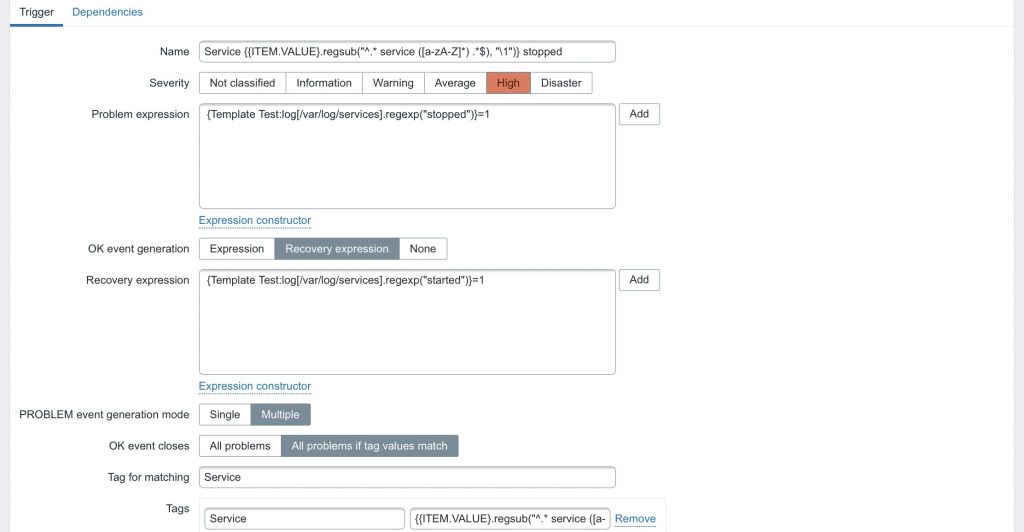
Donc lorsque Zabbix détectera une ligne comportant « service XX stopped », alors il va créer l’alerte pour le service XX et y associer le tag XX.
Cette alerte ne sera clôturé qu’à l’apparition de la ligne « service XX started ».
Un exemple :

Pour reprendre notre exemple :
… 10/Aug/2016:06:25:30 service Jira stopped 10/Aug/2016:06:25:32 service MySQL stopped 10/Aug/2016:06:26:11 service MySQL started 10/Aug/2016:06:26:22 service Redis stopped 10/Aug/2016:06:26:58 service Redis started 10/Aug/2016:06:27:31 service Jira started …
Ligne 1 : le service Jira est arrêté, donc création d’une alerte « Service Jira stopped » avec le tag « Jira ».
Ligne 2 : le service MySQL est arrêté, donc création d’une alerte « Service MySQL stopped » avec le tag « MySQL ».
Ligne 3 : le service MySQL est démarré, donc clôture de l’alerte « Service MySQL stopped » avec le tag « MySQL ».
Ligne 4 : le service Redis est arrêté, donc création d’une alerte « Service Redis stopped » avec le tag « Redis ».
Ligne 5 : le service Redis est démarré, donc clôture de l’alerte « Service Redis stopped » avec le tag « Redis ».
Ligne 6 : le service J’irai est démarré, donc clôture de l’alerte « Service Jira stopped » avec le tag « Jira ».
Voici donc ce qui nous rend plus efficace à surveiller nos logs.
Bien sûr, si ceux-ci nous le permettent ?